1. Introduction
Imagine yourself standing in front of an exquisite bu et lled with numerous delicacies. Your goal is to try them all out, but you need to decide in what order. What exchange of tastes will maximizethe overall pleasure of your palate?
Although much less pleasurable and subjective, that is the type of problem that query optimizers are called to solve. Given a query, there are many plans that a database management system (DBMS) can follow to process it and produce its answer. All plans are equivalent in terms of their nal output but vary in their cost, i.e., the amount of time that they need to run. What is the plan that needs the least amount of time?
Such query optimization is absolutely necessary in a DBMS. The cost di erence between two alternatives can be enormous. For example, consider the following database schema, which will be Partially supported by the National Science Foundation under Grants IRI-9113736 and IRI-9157368 (PYI Award) and by grants from DEC, IBM, HP, AT&T, Informix, and Oracle.
used throughout this chapter:
emp(name,age,sal,dno)
dept(dno,dname, oor,budget,mgr,ano)
acnt(ano,type,balance,bno)
bank(bno,bname,address)
Further, consider the following very simple SQL query:
select name, floor
from emp, dept
where emp.dno=dept.dno and sal>100K.
Assume the characteristics below for the database contents, structure, and run-time environment:

Consider the following three di erent plans:
P1 Through the B+-tree nd all tuples of emp that satisfy the selection on emp.sal. For each one, use the hashing index to nd the corresponding dept tuples. (Nested loops, using the index on both relations.) P2 For each dept page, scan the entire emp relation. If an emp tuple agrees on the dno attribute with a tuple on the dept page and satis es the selection on emp.sal, then the emp-dept tuple pair appears in the result. (Page-level nested loops, using no index.)
P3 For each dept tuple, scan the entire emp relation and store all emp-dept tuple pairs.
Then, scan this set of pairs and, for each one, check if it has the same values in the two dno attributes and satis es the selection on emp.sal. (Tuple-level formation of the cross product, with subsequent scan to test the join and the selection.) Calculating the expected I/O costs of these three plans shows the tremendous di erence in e ciency that equivalent plans may have. P1 needs 0.32 seconds, P2 needs a bit more than an hour, and P3 needs more than a whole day. Without query optimization, a system may choose plan P2 or P3 to execute this query with devastating results. Query optimizers, however, examine \all" alternatives, so they should have no trouble choosing P1 to process the query.
The path that a query traverses through a DBMS until its answer is generated is shown in Figure 1. The system modules through which it moves have the following functionality:
- The Query Parser checks the validity of the query and then translates it into an internal form, usually a relational calculus expression or something equivalent.
- The Query Optimizer examines all algebraic expressions that are equivalent to the given query and chooses the one that is estimated to be the cheapest.
- The Code Generator or the Interpreter transforms the access plan generated by the optimizer into calls to the query processor.
- The Query Processor actually executes the query.
Queries are posed to a DBMS by interactive users or by programs written in general-purpose programming languages (e.g., C/C++, Fortran, PL-1) that have queries embedded in them. An interactive (ad hoc) query goes through the entire path shown in Figure 1. On the other hand, an embedded query goes through the rst three steps only once, when the program in which it is em-

bedded is compiled (compile time). The code produced by the Code Generator is stored in the database and is simply invoked and executed by the Query Processor whenever control reaches that query during the program execution (run time). Thus, independent of the number of times an embedded query needs to be executed, optimization is not repeated until database updates make the access plan invalid (e.g., index deletion) or highly suboptimal (e.g., extensive changes in database contents). There is no real di erence between optimizing interactive or embedded queries, so we make no distinction between the two in this chapter.
The area of query optimization is very large within the database eld. It has been studied in a great variety of contexts and from many di erent angles, giving rise to several diverse solutions in each case. The purpose of this chapter is to primarily discuss the core problems in query optimization and their solutions, and only touch upon the wealth of results that exist beyond that. More speci cally, we concentrate on optimizing a single at SQL query with `and' as the only boolean connective in its quali cation (also known as conjunctive query, select-project-join query, or nonrecursive Horn clause) in a centralized relational DBMS, assuming that full knowledge of the run-time environment exists at compile time. Likewise, we make no attempt to provide a complete survey of the literature, in most cases providing only a few example references. More extensive surveys can be found elsewhere [JK84, MCS88].
The rest of the chapter is organized as follows. Section 2 presents a modular architecture for a query optimizer and describes the role of each module in it. Section 3 analyzes the choices that exist in the shapes of relational query access plans, and the restrictions usually imposed by current optimizers to make the whole process more manageable. Section 4 focuses on the dynamic programming search strategy used by commercial query optimizers and brie y describes alternative strategies that have been proposed. Section 5 de nes the problem of estimating the sizes of query results and/or the frequency distributions of values in them, and describes in detail histograms, which represent the statistical information typically used by systems to derive such estimates.
Section 6 discusses query optimization in non-centralized environments, i.e., parallel and distributed DBMSs. Section 7 brie y touches upon several advanced types of query optimization that have been proposed to solve some hard problems in the area. Finally, Section 8 summarizes the chapter and raises some questions related to query optimization that still have no good answer.
2 Query Optimizer Architecture
2.1 Overall Architecture
In this section, we provide an abstraction of the query optimization process in a DBMS. Given a database and a query on it, several execution plans exist that can be employed to answer the query.
In principle, all the alternatives need to be considered so that the one with the best estimated performance is chosen. An abstraction of the process of generating and testing these alternatives
is shown in Figure 2, which is essentially a modular architecture of a query optimizer. Although one could build an optimizer based on this architecture, in real systems, the modules shown do not always have so clear-cut boundaries as in Figure 2. Based on Figure 2, the entire query optimization

process can be seen as having two stages: rewriting and planning. There is only one module in the rst stage, the Rewriter, whereas all other modules are in the second stage. The functionality of each of the modules in Figure 2 is analyzed below.
2.2 Module Functionality
Rewriter: This module applies transformations to a given query and produces equivalent queries
that are hopefully more e cient, e.g., replacement of views with their de nition, attening out of
nested queries, etc. The transformations performed by the Rewriter depend only on the declarative, i.e., static, characteristics of queries and do not take into account the actual query costs for the speci c DBMS and database concerned. If the rewriting is known or assumed to always be bene cial, the original query is discarded; otherwise, it is sent to the next stage as well. By the nature of the rewriting transformations, this stage operates at the declarative level.
Planner: This is the main module of the ordering stage. It examines all possible execution plans for each query produced in the previous stage and selects the overall cheapest one to be used to generate the answer of the original query. It employs a search strategy, which examines the space of execution plans in a particular fashion. This space is determined by two other modules of the optimizer, the Algebraic Space and the Method-Structure Space. For the most part, these two modules and the search strategy determine the cost, i.e., running time, of the optimizer itself, which should be as low as possible. The execution plans examined by the Planner are compared based on estimates of their cost so that the cheapest may be chosen. These costs are derived by the last two modules of the optimizer, the Cost Model and the Size-Distribution Estimator.
Algebraic Space: This module determines the action execution orders that are to be considered
by the Planner for each query sent to it. All such series of actions produce the same query answer, but usually di er in performance. They are usually represented in relational algebra as formulas or in tree form. Because of the algorithmic nature of the objects generated by this module and sent to the Planner, the overall planning stage is characterized as operating at the procedural level.
Method-Structure Space: This module determines the implementation choices that exist for the execution of each ordered series of actions speci ed by the Algebraic Space. This choice is related to the available join methods for each join (e.g., nested loops, merge scan, and hash join), if supporting data structures are built on the y, if/when duplicates are eliminated, and other implementation characteristics of this sort, which are predetermined by the DBMS implementation.
This choice is also related to the available indices for accessing each relation, which is determined by the physical schema of each database stored in its catalogs. Given an algebraic formula or tree from the Algebraic Space, this module produces all corresponding complete execution plans, which specify the implementation of each algebraic operator and the use of any indices. Cost Model: This module speci es the arithmetic formulas that are used to estimate the cost of execution plans. For every di erent join method, for every di erent index type access, and in general for every distinct kind of step that can be found in an execution plan, there is a formula that gives its cost. Given the complexity of many of these steps, most of these formulas are simple approximations of what the system actually does and are based on certain assumptions regarding issues like bu er management, disk-cpu overlap, sequential vs. random I/O, etc. The most impor- tant input parameters to a formula are the size of the bu er pool used by the corresponding step, the sizes of relations or indices accessed, and possibly various distributions of values in these rela- tions. While the rst one is determined by the DBMS for each query, the other two are estimated by the Size-Distribution Estimator.
Size-Distribution Estimator: This module speci es how the sizes (and possibly frequency dis- tributions of attribute values) of database relations and indices as well as (sub)query results are
estimated. As mentioned above, these estimates are needed by the Cost Model. The speci c es- timation approach adopted in this module also determines the form of statistics that need to be maintained in the catalogs of each database, if any.
2.3 Description Focus
Of the six modules of Figure 2, three are not discussed in any detail in this chapter: the Rewriter,
the Method-Structure Space, and the Cost Model. The Rewriter is a module that exists in some commercial DBMSs (e.g., DB2-Client/Server and Illustra), although not in all of them. Most of the transformations normally performed by this module are considered an advanced form of query optimization, and not part of the core (planning) process. The Method-Structure Space speci es alternatives regarding join methods, indices, etc., which are based on decisions made outside the development of the query optimizer and do not really a ect much of the rest of it. For the Cost Model, for each alternative join method, index access, etc., o ered by the Method-Structure Space,either there is a standard straightforward formula that people have devised by simple accounting of the corresponding actions (e.g., the formula for tuple-level nested loops join) or there are numerous variations of formulas that people have proposed and used to approximate these actions (e.g., formulas for nding the tuples in a relation having a random value in an attribute). In either case, the derivation of these formulas is not considered an intrinsic part of the query optimization eld. For these reasons, we do not discuss these three modules any further until Section 7, where some Rewriter transformations are described. The following three sections provide a detailed description of the Algebraic Space, the Planner, and the Size-Distribution Estimator modules, respectively.
3 Algebraic Space
As mentioned above, a at SQL query corresponds to a select-project-join query in relational algebra. Typically, such an algebraic query is represented by a query tree whose leaves are database relations and non-leaf nodes are algebraic operators like selections (denoted by ), projections (denoted by ), and joins1 (denoted by 1). An intermediate node indicates the application of the corresponding operator on the relations generated by its children, the result of which is then sent further up. Thus, the edges of a tree represent data ow from bottom to top, i.e., from the leaves, which correspond to data in the database, to the root, which is the nal operator producing the query answer. Figure 3 gives three examples of query trees for the query
select name, floor
from emp, dept
where emp.dno=dept.dno and sal>100K .
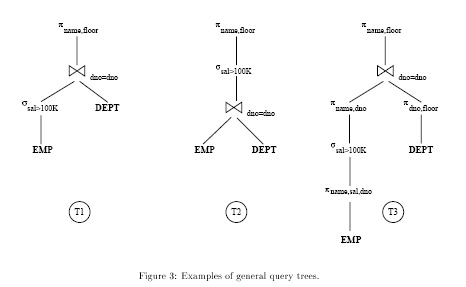
For a complicated query, the number of all query trees may be enormous. To reduce the size of the space that the search strategy has to explore, DBMSs usually restrict the space in several ways. The rst typical restriction deals with selections and projections:
R1 Selections and projections are processed on the y and almost never generate inter- mediate relations. Selections are processed as relations are accessed for the rst time. Projections are processed as the results of other operators are generated. For example, plan P1 of Section 1 satis es restriction R1: the index scan of emp nds emp tuples that satisfy the selection on emp.sal on they and attempts to join only those; furthermore, the projection on the result attributes occurs as the join tuples are generated. For queries with no join, R1 is moot. For queries with joins, however, it implies that all operations are dealt with as part of join execution. Restriction R1 eliminates only suboptimal query trees, since separate processing of selections and projections incurs additional costs. Hence, the Algebraic Space module speci es alternative query trees with join operators only, selections and projections being implicit.
Given a set of relations to be combined in a query, the set of all alternative join trees is deter- mined by two algebraic properties of join: commutativity (R1 1 R2 R2 1 R1) and associativity ((R1 1 R2) 1 R3 R1 1 (R2 1 R3)). The rst determines which relation will be inner and which outer in the join execution. The second determines the order in which joins will be executed. Even with the R1 restriction, the alternative join trees that are generated by commutativity and associativity is very large, (N!) for N relations. Thus, DBMSs usually further restrict the space that must be explored. In particular, the second typical restriction deals with cross products. R2 Cross products are never formed, unless the query itself asks for them. Relations are combined always through joins in the query.
For example, consider the following query:
select name, floor, balance, address
from emp, dept, acnt, bank
where emp.dno=dept.dno and dept.ano=acnt.ano and acnt.bno=bank.bno
Figure 5 shows three possible cross-product-free join trees that can be used to combine the emp,
dept, acnt, and bank relations to answer the query. Tree T1 satis es restriction R3, whereas trees
T2 and T3 do not, since they have at least one join with an intermediate result as the inner relation.
Because of their shape (Figure 5) join trees that satisfy restriction R3, e.g., tree T1, are called left- deep. Trees that have their outer relation always being a database relation, e.g., tree T2, are called right-deep. Trees with at least one join between two intermediate results, e.g., tree T3, are called bushy. Restriction R3 is of a more heuristic nature than R1 and R2 and may well eliminate the optimal plan in several cases. It has been claimed that most often the optimal left-deep tree is not much more expensive than the optimal tree overall. The typical arguments used are two:
- Having original database relations as inners increases the use of any preexisting indices.

In summary, typical query optimizers make restrictions R1, R2, and R3 to reduce the size of the space they explore. Hence, unless otherwise noted, our descriptions follow these restrictions as well.
Computers are now no longer only membranous Humans Used for their jobs, but as already started to operate to replace most of the human work does not Require That thinking and routines. Further development experts are trying to replace the system of the human brain into a computer system.
Neural network is one of the information processing system Designed to mimic the way human brains work in conducting a problem with the process of learning through on their synaptic weight changes. Neural network is Able to identify activities based on past data. Past data will from be studied by artificial neural networks capable That have to inform decisions on That data have not been studied.
Neural network is defined as a system of information processing have That resembling human neural Characteristics. Neural network is created as a mathematical model of understanding generelization Humans (human cognition) based upon assumptions Mutation
1st. Information processing occurs in simple elements Called neurons.
2. Signal Flow Between the nerve cells / neurons via a link connection.
3. Each connection link has a weight Which Will Be Used to double / multiplying sent through the signal.
4. Each nerve cell function will of activation apply to the weighted sum of signals coming to him "to determine the output signal.
Artificial neural networks have a large excess dibandingakan with another calculation method, namely:
1st. The ABILITY even though on their acquired knowledge in a disturbance and uncertain conditions.
2. Ability to present knowledge flexibly.
3. The ABILITY to Provide tolerance to a distortion (error / faults), Nowhere a small disturbance in the data Can be regarded as noise (shake) them.
4. Ability to process knowledge efficiently for wearing a parallel system, so That Time needed to operate Them Is Becoming Shorter.
With a very good level of ABILITY, Some applications of artificial neural network is suitable to apply to:
1st. Classification, selecting one input specific data into one category specified.
2. Association, describes an object as a whole only with a part of another object.
3. Self organizing, ABILITY to process the input data without having to have the data as a target.
4. Optimization, finding an answer or solution best That Can optimizing so often with a cost function (the optimizer).
Characteristic determined by the artificial neural network;
1st. The pattern of relations Between neurons (Called the network architecture)
2. The method to determine the connection weights (Called training or learning network)
3. Activation function.
The basic concept of neural networks
Arsitecture division of neural networks Can be seen from the number of working framework and interconnection schemes. Working framework artificial neural network bias seen from the number of layers and the number of nodes on all layers.
Layer neural networks Compiler Can be divided into three, namely;
1st. Input layer: Node-node in the input layer of input units is Called. Input unit receives input from the outside world. Input is entered is representation of a problem.
2. Hidden layer: Node-node in the hidden layers, hidden units is Called. The output of this layer is not directly observable.
3. Output layer: Node-node at the output layer of output units is Called. Output or the output of this layer is the output of neural networks to a problem.
Most of the neural network adjusts its weight During the weight-training procedure. Training Can be guided training (supervised training) Nowhere pair targets the required inputs for Each pattern was Trained. The second kind is not guided training (unsupervised training). In this method, the adjustment of weights (as a response to the input), the target need not be accompanied. In no supervised training, the network classifies the existing patterns based on category similarity.
The difference is the use of guided training class membership information of Each training example. With this information unsupervised training algorithm for pattern classification cans detect the error as a feedback in the network.
While not supervised neural network training based on how to Modify parameters in a way That masks any sense. In this training model, neural networks do not utilize of membership is no class of training examples, but use the information in a group of neurons to local Modify parameters.
Artificial neural network to solve the problem through a process of learning from examples. Usually the artificial neural network is given a set of training patterns Which parties in a set of sample patterns. From the example neural network learning process.
Can Humans learn, understand, and remember it fully, partially, and Sometimes not all, depending on the person's capacity to learn and store information in on their brains. As the brain stores information is not in full then it is likely to lose the information stored in the brain it will from be great.
The main difference, Between the human brain with an artificial neural network is biased forget That the human brain, whereas neural networks are not likely to forget. Trained neural networks have been Crops Will Be Deeply and Permanently serve targeted information within the cells. Nerve cells in the neural networks Can not be damaged while the human nerve cells is likely corrupted. When nerve cells in the human brain is damaged then the information contained therein will of will of some lost and people forget the information contained therein.
Data and information on human cells is stored in a structured unit in the brain. While the neural network, data and information stored in the weights and biases shape files so That Can be the Anticipation of potential future damage by using a back-up or data backups.
Another difference is the accuracy. When finished Trained neural network, then he Will Be Able to solve the problem of premises The Same Same results even if the problem is repeated Arm-time, while the Humans are not Able to do so.
In The Same unit length of artificial neural networks Quickly Can transmit more information than the human brain. Because this is the work in electronic neural networks while the human brain works chemically.
The Following is a complete comparison Between the capabilities Possessed by the human brain with a CPU:

Neural network is one of the information processing system Designed to mimic the way human brains work in conducting a problem with the process of learning through on their synaptic weight changes. Neural network is Able to identify activities based on past data. Past data will from be studied by artificial neural networks capable That have to inform decisions on That data have not been studied.
Neural network is defined as a system of information processing have That resembling human neural Characteristics. Neural network is created as a mathematical model of understanding generelization Humans (human cognition) based upon assumptions Mutation
1st. Information processing occurs in simple elements Called neurons.
2. Signal Flow Between the nerve cells / neurons via a link connection.
3. Each connection link has a weight Which Will Be Used to double / multiplying sent through the signal.
4. Each nerve cell function will of activation apply to the weighted sum of signals coming to him "to determine the output signal.
Artificial neural networks have a large excess dibandingakan with another calculation method, namely:
1st. The ABILITY even though on their acquired knowledge in a disturbance and uncertain conditions.
2. Ability to present knowledge flexibly.
3. The ABILITY to Provide tolerance to a distortion (error / faults), Nowhere a small disturbance in the data Can be regarded as noise (shake) them.
4. Ability to process knowledge efficiently for wearing a parallel system, so That Time needed to operate Them Is Becoming Shorter.
With a very good level of ABILITY, Some applications of artificial neural network is suitable to apply to:
1st. Classification, selecting one input specific data into one category specified.
2. Association, describes an object as a whole only with a part of another object.
3. Self organizing, ABILITY to process the input data without having to have the data as a target.
4. Optimization, finding an answer or solution best That Can optimizing so often with a cost function (the optimizer).
Characteristic determined by the artificial neural network;
1st. The pattern of relations Between neurons (Called the network architecture)
2. The method to determine the connection weights (Called training or learning network)
3. Activation function.
The basic concept of neural networks
Arsitecture division of neural networks Can be seen from the number of working framework and interconnection schemes. Working framework artificial neural network bias seen from the number of layers and the number of nodes on all layers.
Layer neural networks Compiler Can be divided into three, namely;
1st. Input layer: Node-node in the input layer of input units is Called. Input unit receives input from the outside world. Input is entered is representation of a problem.
2. Hidden layer: Node-node in the hidden layers, hidden units is Called. The output of this layer is not directly observable.
3. Output layer: Node-node at the output layer of output units is Called. Output or the output of this layer is the output of neural networks to a problem.
Most of the neural network adjusts its weight During the weight-training procedure. Training Can be guided training (supervised training) Nowhere pair targets the required inputs for Each pattern was Trained. The second kind is not guided training (unsupervised training). In this method, the adjustment of weights (as a response to the input), the target need not be accompanied. In no supervised training, the network classifies the existing patterns based on category similarity.
The difference is the use of guided training class membership information of Each training example. With this information unsupervised training algorithm for pattern classification cans detect the error as a feedback in the network.
While not supervised neural network training based on how to Modify parameters in a way That masks any sense. In this training model, neural networks do not utilize of membership is no class of training examples, but use the information in a group of neurons to local Modify parameters.
Artificial neural network to solve the problem through a process of learning from examples. Usually the artificial neural network is given a set of training patterns Which parties in a set of sample patterns. From the example neural network learning process.
Can Humans learn, understand, and remember it fully, partially, and Sometimes not all, depending on the person's capacity to learn and store information in on their brains. As the brain stores information is not in full then it is likely to lose the information stored in the brain it will from be great.
The main difference, Between the human brain with an artificial neural network is biased forget That the human brain, whereas neural networks are not likely to forget. Trained neural networks have been Crops Will Be Deeply and Permanently serve targeted information within the cells. Nerve cells in the neural networks Can not be damaged while the human nerve cells is likely corrupted. When nerve cells in the human brain is damaged then the information contained therein will of will of some lost and people forget the information contained therein.
Data and information on human cells is stored in a structured unit in the brain. While the neural network, data and information stored in the weights and biases shape files so That Can be the Anticipation of potential future damage by using a back-up or data backups.
Another difference is the accuracy. When finished Trained neural network, then he Will Be Able to solve the problem of premises The Same Same results even if the problem is repeated Arm-time, while the Humans are not Able to do so.
In The Same unit length of artificial neural networks Quickly Can transmit more information than the human brain. Because this is the work in electronic neural networks while the human brain works chemically.
The Following is a complete comparison Between the capabilities Possessed by the human brain with a CPU:

Those who are into digital photography are almost certainly experts when it comes to PhotoShop. This software is essential in editing normal photos in order to achieve perfect and artistic photographs using different kinds of effects such as the appropriate color saturation.
However, not all individuals have the knowledge when it comes to PhotoShop and a lot of people want to know how to transform a simple photograph into an artistic piece. If you want to learn the tricks of PhotoShop, you just have to use certain books and PhotoShop tutorials. Most people rely in PhotoShop tutorials especially in learning new things because with PhotoShop tutorials, they do not need to go through different books and seek advice from their friends.
PhotoShop tutorials are designed to help everyone be familiar with the software. You can find these free tutorials on the Internet, which are usually divided into numerous categories for you to be able to use them faster and easier. Categories include photography tutorials, the basics category, special effects, texturing category and web design tutorials. There are other websites providing different versions of the program where you can learn the entire set of lessons made for the type of PhotoShop you use. With PhotoShop tutorials, you can easily learn tricks and techniques in video, graphics, films and special effects.
There are countless websites that offer PhotoShop tutorials. If you are just starting to learn the basics, there are tutorials that are developed for those needs. You can easily learn how to make simple changes such as how to remove red eyes, change hair color, know the importance of layers, retouching pictures and knowing information about different tools necessary for photograph modifications.
If you are in need of comprehensive instructions on how to use PhotoShop, the Internet can provide you countless websites such as www.tutorialsite.org, which can help you, learn how to manipulate and improve your digital photographs. Most tutorial sites offer downloadable files and instructions where you can get useful information.
The first thing you need to learn before starting to create a new file is to know how to navigate the software. With PhotoShop tutorials , you will easily learn the different actions and icons found in the menu bar, palette, toolbox and status bar. Another important section of the tutorial is the part where you can learn how to work with your photos and existing documents. In this part, you will be able to learn how to enhance or improve your document and pictures in your personal computer. You can open, crop, resize, view and save documents with ease. In addition, you can learn different ways on how to edit photographs.
One of the most interesting elements in PhotoShop tutorials is the part about the different tools essential in enhancing, creating and retouching photographs. In this section, you will be able to learn how to have fun with colors as well as know more complex tools including the lasso section tools, the wand, layering tools and eyedropper.
In addition, Website owners can also benefit from PhotoShop tutorials especially in advanced tutorials where they can learn ways on how on create a hosting server using PhotoShop, make introduction pages and navigation bars easily. You can choose from a wide range of tutorials that are not restricted to PhotoShop enthusiasts only but also for everyone who are in need of useful PhotoShop information.
Though there are hundreds of tutorials on the internet, it is recommended to focus on a the basic tutorial sites if you are really interested in learning something in particular and eventually search for more advanced tutorials. This way, you will be able to learn everything slowly. With free PhotoShop tutorials, it won't be difficult for you to learn new things everyday. Learning about PhotoShop is essential especially with the technological advancement. You may not dream of becoming a world-class graphic artist but having enough knowledge on PhotoShop can give you the edge in your career.
However, not all individuals have the knowledge when it comes to PhotoShop and a lot of people want to know how to transform a simple photograph into an artistic piece. If you want to learn the tricks of PhotoShop, you just have to use certain books and PhotoShop tutorials. Most people rely in PhotoShop tutorials especially in learning new things because with PhotoShop tutorials, they do not need to go through different books and seek advice from their friends.
PhotoShop tutorials are designed to help everyone be familiar with the software. You can find these free tutorials on the Internet, which are usually divided into numerous categories for you to be able to use them faster and easier. Categories include photography tutorials, the basics category, special effects, texturing category and web design tutorials. There are other websites providing different versions of the program where you can learn the entire set of lessons made for the type of PhotoShop you use. With PhotoShop tutorials, you can easily learn tricks and techniques in video, graphics, films and special effects.
There are countless websites that offer PhotoShop tutorials. If you are just starting to learn the basics, there are tutorials that are developed for those needs. You can easily learn how to make simple changes such as how to remove red eyes, change hair color, know the importance of layers, retouching pictures and knowing information about different tools necessary for photograph modifications.
If you are in need of comprehensive instructions on how to use PhotoShop, the Internet can provide you countless websites such as www.tutorialsite.org, which can help you, learn how to manipulate and improve your digital photographs. Most tutorial sites offer downloadable files and instructions where you can get useful information.
The first thing you need to learn before starting to create a new file is to know how to navigate the software. With PhotoShop tutorials , you will easily learn the different actions and icons found in the menu bar, palette, toolbox and status bar. Another important section of the tutorial is the part where you can learn how to work with your photos and existing documents. In this part, you will be able to learn how to enhance or improve your document and pictures in your personal computer. You can open, crop, resize, view and save documents with ease. In addition, you can learn different ways on how to edit photographs.
One of the most interesting elements in PhotoShop tutorials is the part about the different tools essential in enhancing, creating and retouching photographs. In this section, you will be able to learn how to have fun with colors as well as know more complex tools including the lasso section tools, the wand, layering tools and eyedropper.
In addition, Website owners can also benefit from PhotoShop tutorials especially in advanced tutorials where they can learn ways on how on create a hosting server using PhotoShop, make introduction pages and navigation bars easily. You can choose from a wide range of tutorials that are not restricted to PhotoShop enthusiasts only but also for everyone who are in need of useful PhotoShop information.
Though there are hundreds of tutorials on the internet, it is recommended to focus on a the basic tutorial sites if you are really interested in learning something in particular and eventually search for more advanced tutorials. This way, you will be able to learn everything slowly. With free PhotoShop tutorials, it won't be difficult for you to learn new things everyday. Learning about PhotoShop is essential especially with the technological advancement. You may not dream of becoming a world-class graphic artist but having enough knowledge on PhotoShop can give you the edge in your career.
by: Jeyanth Watson
I recently finished creating my latest website, and since I am a designer, not a coder, I often find the need to seek the services of a freelance IT professional. There are several good sites out there that can easily help you find the help your looking for. There are quality professionals available that provide everything from logo creation to website design, to marketing and advertising. There are people that can help you from beginning to end during your entire website creation process.
There are literally thousands of IT professionals and not-so-professionals out there ready to take on your project. I have had wonderful experiences and slightly less than wonderful experiences in these situations, and want to give you some help in finding IT professionals that can save you money, but sometimes more importantly, lots of time.
1-Get Several Quotes- After you post your project on the boards, you will probably receive a couple quotes within an hour or so. Check each quote carefully; make sure it encompasses EVERYTHING you described in your job posting. Cheaper is NOT synonymous with better so make sure you get are getting quality help at a reasonable price. Don't be afraid to pay what the job is worth. These people have to make a living and if you take care of them they will take care of you. If you go looking for the cheapest bid available often you will find yourself wasting lots of time and sometimes money, and probably having to hire somebody else to go back and re-do what should have be done, or done right, the first time. With that being said..
2- Check Their Qualifications - Once you receive several quotes and have a good idea what your budget is probably going to be, check their qualifications. All Freelancers will have a profile page available when they submit a quote for your project. MAKE SURE THEY ARE QUALIFIED TO PERFORM THE PARTICULAR TYPE OF WORK YOU NEED. More than likely you will receive lots of bids on every project you post. And most of the time you will receive quotes from people that are not completely qualified to perform the work you need. One thing to keep in mind, ANYBODY CAN BE A FREELANCER, and lots of people will say they have the skills required to perform the task but may only have a little knowledge about a particular skill and assume they can "figure it out" as they go. And they quite possibly may be able to do that in some situations. The problem with that is: guess what you're doing while they are "figuring it out"?......waiting. And sometimes time can be more valuable than money. I have given freelancers days and sometimes a week or so to complete a task that would have taken a QUALIFIED person 2 days to complete. A higher skill level is more valuable so sometimes you may have to pay a little extra to acquire the more qualified person. I have even awarded a project to an unqualified person, waited a week for a 2 day project, only to find out they were unable to complete the project and had to hire someone else. With that being said....
3-Check Their Feedback-On their profile pages they will have a feedback page. Check their feedback and actually read some of the comments posted. Find out if they are professional, timely and responsive on their projects. See if all work was completed and if they would be hired again on future projects. Make sure you check any negative comments left. But don't let a negative comment sway you from a professional if they have 98% positive feedback and had one bad experience with someone. Sometimes people can expect too much work for their money or aren't descriptive enough in their job post and fail to sufficiently let the IT pro know the full scope of the work needed, and then get upset when they don't receive 15hrs. of work for their $200 bucks. And on the other end, when your project is complete, don't forget to go back and leave feedback for your IT pro. It will help others like yourself find quality, professional help, and it's just simply good business practice.
4-Be Descriptive In Your Job Post-I can't stress this one enough. One key to making sure your project runs smoothly is making sure both sides understand exactly what the job at hand is. Don't leave anything out of your post. If you know something is going to be a challenge or if there are other situations attached to the current problem, make sure you let them know up front what they are getting into. Like I said in tip #3 if your post is not descriptive enough and the IT pro ends up "opening a can of worms" on your project, you will only get the amount of work your budget allots, often leaving your project unfinished or poorly completed, or they will be forced to request additional funds, or they may refuse the project all together leaving you to post the project again, go through the whole process of finding someone, again, and wasting lots of time that wasn't necessary in the first place.
5-Find Good Help and Stick With It.-When someone does a professional, quality job on one of your projects, reward them by using them again in the future (if it doesn't conflict with tip #2). You can build professional relationships and fore go all the "weeding out" processes on future projects and save yourself some time if you have quality pros that you can consistently rely on. And they may feel inclined to put in a little extra effort on your next project and can add to the overall quality of the job.
Hopefully these tips will help save you time and money and most importantly will allow you to achieve your ultimate goal, which is finishing your project in a timely and professional manner with the highest quality possible. Guru.Com, ODesk.com, & Elance.com are a few good places to start when beginning your search. Freelance work can be a great solution to your IT needs and is most effective when the process is carefully monitored and a few guidelines are followed.
There are literally thousands of IT professionals and not-so-professionals out there ready to take on your project. I have had wonderful experiences and slightly less than wonderful experiences in these situations, and want to give you some help in finding IT professionals that can save you money, but sometimes more importantly, lots of time.
1-Get Several Quotes- After you post your project on the boards, you will probably receive a couple quotes within an hour or so. Check each quote carefully; make sure it encompasses EVERYTHING you described in your job posting. Cheaper is NOT synonymous with better so make sure you get are getting quality help at a reasonable price. Don't be afraid to pay what the job is worth. These people have to make a living and if you take care of them they will take care of you. If you go looking for the cheapest bid available often you will find yourself wasting lots of time and sometimes money, and probably having to hire somebody else to go back and re-do what should have be done, or done right, the first time. With that being said..
2- Check Their Qualifications - Once you receive several quotes and have a good idea what your budget is probably going to be, check their qualifications. All Freelancers will have a profile page available when they submit a quote for your project. MAKE SURE THEY ARE QUALIFIED TO PERFORM THE PARTICULAR TYPE OF WORK YOU NEED. More than likely you will receive lots of bids on every project you post. And most of the time you will receive quotes from people that are not completely qualified to perform the work you need. One thing to keep in mind, ANYBODY CAN BE A FREELANCER, and lots of people will say they have the skills required to perform the task but may only have a little knowledge about a particular skill and assume they can "figure it out" as they go. And they quite possibly may be able to do that in some situations. The problem with that is: guess what you're doing while they are "figuring it out"?......waiting. And sometimes time can be more valuable than money. I have given freelancers days and sometimes a week or so to complete a task that would have taken a QUALIFIED person 2 days to complete. A higher skill level is more valuable so sometimes you may have to pay a little extra to acquire the more qualified person. I have even awarded a project to an unqualified person, waited a week for a 2 day project, only to find out they were unable to complete the project and had to hire someone else. With that being said....
3-Check Their Feedback-On their profile pages they will have a feedback page. Check their feedback and actually read some of the comments posted. Find out if they are professional, timely and responsive on their projects. See if all work was completed and if they would be hired again on future projects. Make sure you check any negative comments left. But don't let a negative comment sway you from a professional if they have 98% positive feedback and had one bad experience with someone. Sometimes people can expect too much work for their money or aren't descriptive enough in their job post and fail to sufficiently let the IT pro know the full scope of the work needed, and then get upset when they don't receive 15hrs. of work for their $200 bucks. And on the other end, when your project is complete, don't forget to go back and leave feedback for your IT pro. It will help others like yourself find quality, professional help, and it's just simply good business practice.
4-Be Descriptive In Your Job Post-I can't stress this one enough. One key to making sure your project runs smoothly is making sure both sides understand exactly what the job at hand is. Don't leave anything out of your post. If you know something is going to be a challenge or if there are other situations attached to the current problem, make sure you let them know up front what they are getting into. Like I said in tip #3 if your post is not descriptive enough and the IT pro ends up "opening a can of worms" on your project, you will only get the amount of work your budget allots, often leaving your project unfinished or poorly completed, or they will be forced to request additional funds, or they may refuse the project all together leaving you to post the project again, go through the whole process of finding someone, again, and wasting lots of time that wasn't necessary in the first place.
5-Find Good Help and Stick With It.-When someone does a professional, quality job on one of your projects, reward them by using them again in the future (if it doesn't conflict with tip #2). You can build professional relationships and fore go all the "weeding out" processes on future projects and save yourself some time if you have quality pros that you can consistently rely on. And they may feel inclined to put in a little extra effort on your next project and can add to the overall quality of the job.
Hopefully these tips will help save you time and money and most importantly will allow you to achieve your ultimate goal, which is finishing your project in a timely and professional manner with the highest quality possible. Guru.Com, ODesk.com, & Elance.com are a few good places to start when beginning your search. Freelance work can be a great solution to your IT needs and is most effective when the process is carefully monitored and a few guidelines are followed.
by: John Chilton
Search engine optimization is the process done to generate traffic through search engines. It became a need for websites because 80%-90% of visitors come from major search engines. Higher rankings mean greater number of visitors. The same concept applies to blogs. However, many blog owners are not aware of their chances of being more visible on the web. They just update it once in a while and that's it. Considering the great number of blogs on the net today, from personal to corporate blogs, all their efforts will just go to waste if they do not optimize it.
Yes, blogs can be optimized, too. It should be done for the benefit both of your readers and search engine spiders. Although the process is quite similar with the standard website search engine optimization, it is a bit different. Here are some tips that you can do to start:
Consider the Design
It is not advisable to use the default template being offered by blog publishing sites. You wouldn't want to bump into a girl in a party wearing the same dress, do you? Same thing goes to blogs. You can hire a designer to do the work for you. If running a tight budget, you can always look for free templates offered by web design companies and you can customize it a little to make it unique.
Yes, blogs can be optimized, too. It should be done for the benefit both of your readers and search engine spiders. Although the process is quite similar with the standard website search engine optimization, it is a bit different. Here are some tips that you can do to start:
Consider the Design
It is not advisable to use the default template being offered by blog publishing sites. You wouldn't want to bump into a girl in a party wearing the same dress, do you? Same thing goes to blogs. You can hire a designer to do the work for you. If running a tight budget, you can always look for free templates offered by web design companies and you can customize it a little to make it unique.
Optimize the Tags
Use the most substantial phrase for your blog in the hard code of the title tag. Also, you have to double check that each entry's title appears on the tile tag. This is sometimes overlooked.
Keywords
You should always use your keywords in the blog post titles and categories. You can also use many categories in one entry if appropriate.
RSS Feed
It is best that you have RSS subscription button available on your blog. This would be more convenient to your readers because it will publish your recently updated work. If your blog publisher don't have RSS automatically available, there are RSS feed button creation tool on the net. But make sure that you place it where the readers can easily see them. You can put it in your sidebar. It is already on the blog owner's prerogative if he/she wants to full or partial RSS.
Use Email
Because there are some people who are not familiar with RSS feeds, go the extra mile and offer them something else with the same benefits. I'm talking about You can have your blog post via email. Free tools are also available online to do this.
Compelling Introduction
Introduction about the blog post is sent out via RSS feed. Make sure that it is compelling to enough to make your readers want to have more of it so that they would click the “more” button and read the entire article. Therefore, it should be interesting.
Check you CSS
It is common that blogs come with overwhelming amount of CSS or Cascading Style Sheets. The solution to this is to place it in an external CSS file to avoid clutter in the main template and for the main entry not to go further down.
Keywords-rich Anchor Texts
In placing links in other sites/blogs and even in putting internal links, make sure that you are using keyword-rich anchor text. Remember that it is always better to use your keywords than “click here” or “more”. It would benefit you when search engine spiders crawl your blog.
Keep Your Posts Bonded
If your blog post is somehow connected to your previous posts, link them to each other. The idea is that if your reader is interested in this particular topic, then he/she probably can also be entertained of a different story with the same subject matter. You can use Related Posts Plugin for this.
Do the same in other blogs. If you see a blog entry or an article on the same issue, make them knowledgeable of your existence by placing a link going to your post.
Purchase a Domain
We all know that blog hosting companies will only be around for such a time. Once they close their business, they will be closing your blog as well. If that happens, where will your loyal followers find you? Or there are change in the domain of your blog host, it will surely affect your rankings.
In case you have limited resources and can only settle to free hosting companies, look for those who offer to display your own domain rather than displaying their own like Wordpress and Blogger.
Proper URL Naming Convention
It is always a bad idea to use dynamic URLs whether on websites or blogs. You should always take advantage of any chance you have to use keywords, without keyword stuffing, including this one. Meaning, instead of using “www.xyzblog.com/?246”, you can consider “www.xyzblog.com/blog-post-keywords-here”. When you cannot do anything about it, use mod rewrite.
Good Navigation
If your blog is just a part of a website, it is not ebough that you a have a link going to your blog's main page. Use the sidebar to syndicate your new posts because the visitors of the website might get interested in your articles if they see the titles.
Fast Page Load
The amount of time involved for a page to load all depends on your host. There are some blogs that takes about half a minute just from the snippet of RSS feed to the full article. You can lose a lot of readers just because of this reason alone.
Moderated Trackbacks and Comments
Spammers are everywhere. They always find a way to abuse your blog by putting non-sense comments with links going to their website. It is annoying and it can also affect your rankings. There are numerous tools available online which you can use to moderate and avoid comment and trackbak spam.
Don't just create a blog to share great information or to prove that you know a lot about the field you are into. Do not settle on the number of followers your blog has. Start to optimize now and see the great changes on the next few months.
Use the most substantial phrase for your blog in the hard code of the title tag. Also, you have to double check that each entry's title appears on the tile tag. This is sometimes overlooked.
Keywords
You should always use your keywords in the blog post titles and categories. You can also use many categories in one entry if appropriate.
RSS Feed
It is best that you have RSS subscription button available on your blog. This would be more convenient to your readers because it will publish your recently updated work. If your blog publisher don't have RSS automatically available, there are RSS feed button creation tool on the net. But make sure that you place it where the readers can easily see them. You can put it in your sidebar. It is already on the blog owner's prerogative if he/she wants to full or partial RSS.
Use Email
Because there are some people who are not familiar with RSS feeds, go the extra mile and offer them something else with the same benefits. I'm talking about You can have your blog post via email. Free tools are also available online to do this.
Compelling Introduction
Introduction about the blog post is sent out via RSS feed. Make sure that it is compelling to enough to make your readers want to have more of it so that they would click the “more” button and read the entire article. Therefore, it should be interesting.
Check you CSS
It is common that blogs come with overwhelming amount of CSS or Cascading Style Sheets. The solution to this is to place it in an external CSS file to avoid clutter in the main template and for the main entry not to go further down.
Keywords-rich Anchor Texts
In placing links in other sites/blogs and even in putting internal links, make sure that you are using keyword-rich anchor text. Remember that it is always better to use your keywords than “click here” or “more”. It would benefit you when search engine spiders crawl your blog.
Keep Your Posts Bonded
If your blog post is somehow connected to your previous posts, link them to each other. The idea is that if your reader is interested in this particular topic, then he/she probably can also be entertained of a different story with the same subject matter. You can use Related Posts Plugin for this.
Do the same in other blogs. If you see a blog entry or an article on the same issue, make them knowledgeable of your existence by placing a link going to your post.
Purchase a Domain
We all know that blog hosting companies will only be around for such a time. Once they close their business, they will be closing your blog as well. If that happens, where will your loyal followers find you? Or there are change in the domain of your blog host, it will surely affect your rankings.
In case you have limited resources and can only settle to free hosting companies, look for those who offer to display your own domain rather than displaying their own like Wordpress and Blogger.
Proper URL Naming Convention
It is always a bad idea to use dynamic URLs whether on websites or blogs. You should always take advantage of any chance you have to use keywords, without keyword stuffing, including this one. Meaning, instead of using “www.xyzblog.com/?246”, you can consider “www.xyzblog.com/blog-post-keywords-here”. When you cannot do anything about it, use mod rewrite.
Good Navigation
If your blog is just a part of a website, it is not ebough that you a have a link going to your blog's main page. Use the sidebar to syndicate your new posts because the visitors of the website might get interested in your articles if they see the titles.
Fast Page Load
The amount of time involved for a page to load all depends on your host. There are some blogs that takes about half a minute just from the snippet of RSS feed to the full article. You can lose a lot of readers just because of this reason alone.
Moderated Trackbacks and Comments
Spammers are everywhere. They always find a way to abuse your blog by putting non-sense comments with links going to their website. It is annoying and it can also affect your rankings. There are numerous tools available online which you can use to moderate and avoid comment and trackbak spam.
Don't just create a blog to share great information or to prove that you know a lot about the field you are into. Do not settle on the number of followers your blog has. Start to optimize now and see the great changes on the next few months.

by: Victoria Phee
About Me

- teknotutorial
- Realistic, full consideration and the principle holds. They try to live life with a high ideal standard. Harbored anger as weakness and try to muffle. They follow strict standards of behavior and / or trying to make the world a l. .. ebih good. # Advantages: holding the ethical, dependable, productive, wise, idealistic, fair, honest, orderly, and self-discipline. # Ugliness: judgmental, inflexible, dogmatic, obsessive-compulsive disorder, like criticizing someone else, too seriously, mastering, anxiety, and envy. # How to get along with me: Do what becomes your responsibility, so I do not have to do the whole job. Acknowledge my achievements. I'm hard on myself. Make sure again that I am fine. Say that you appreciate my advice. Fair and full perhatianlah, like me. Apologize if you're careless. That will help me to forgive. Gently persuade me to relax and laugh at myself if I am uptight, but hear my worries first.